
YOLOv7教學
參考網站:
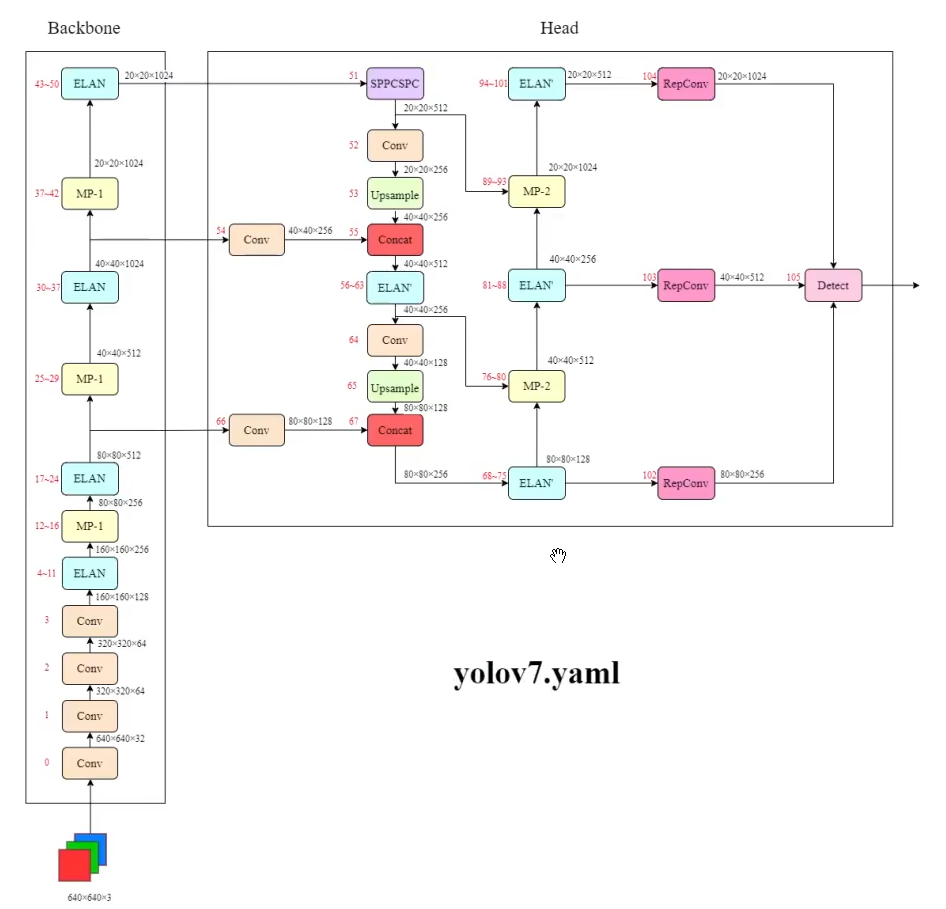
整體結構圖
創新點
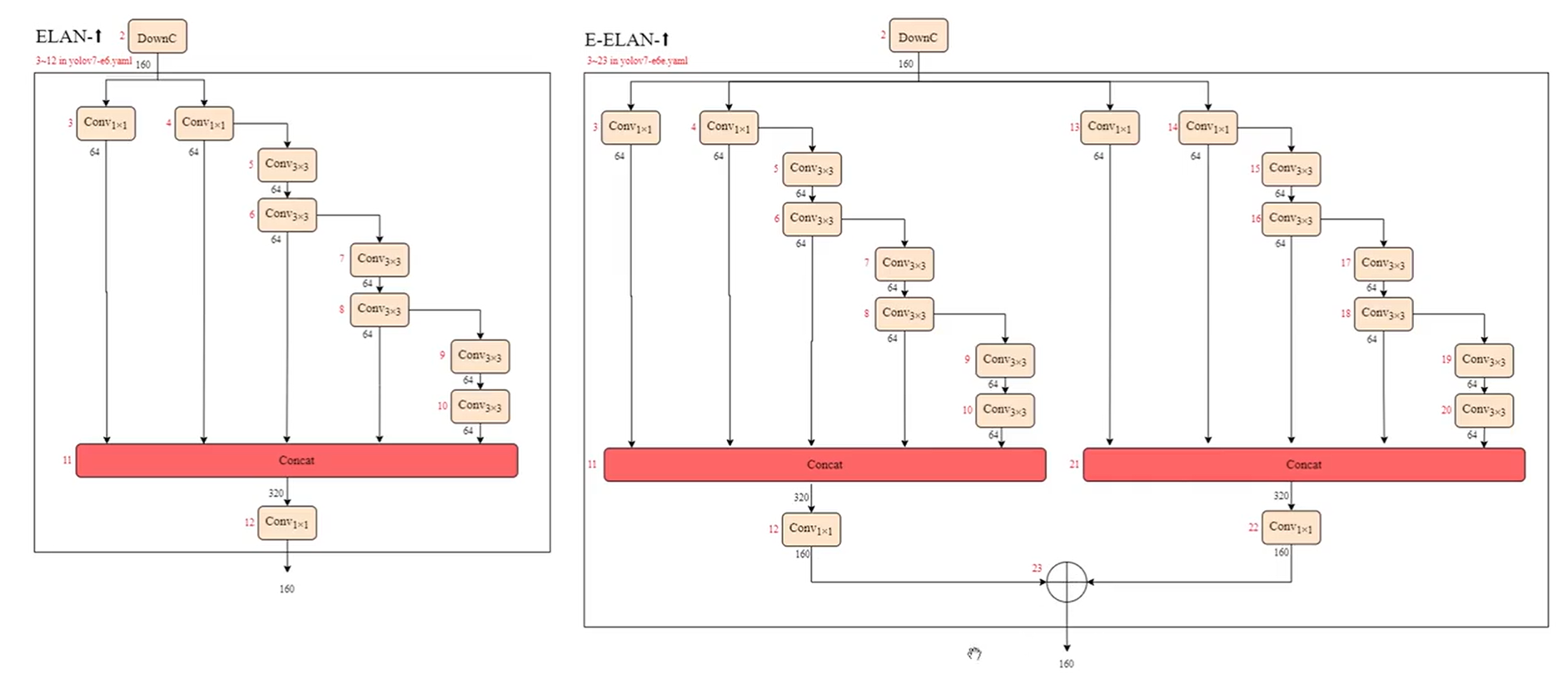
ELAN
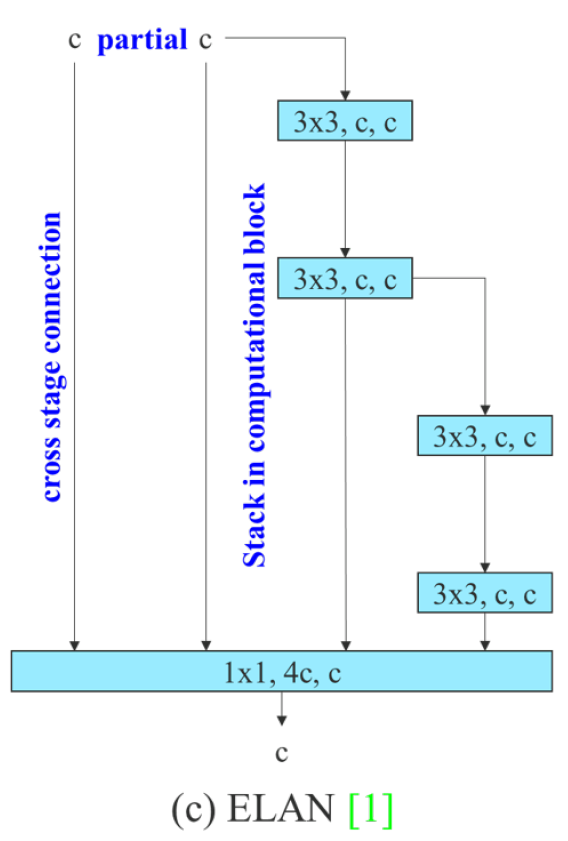
實際實現配置
1 | # [from, number, module, args] |
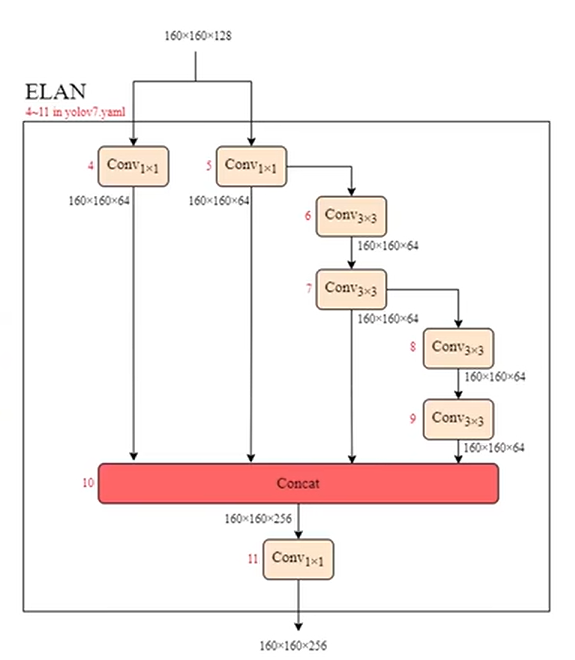
E-ELAN
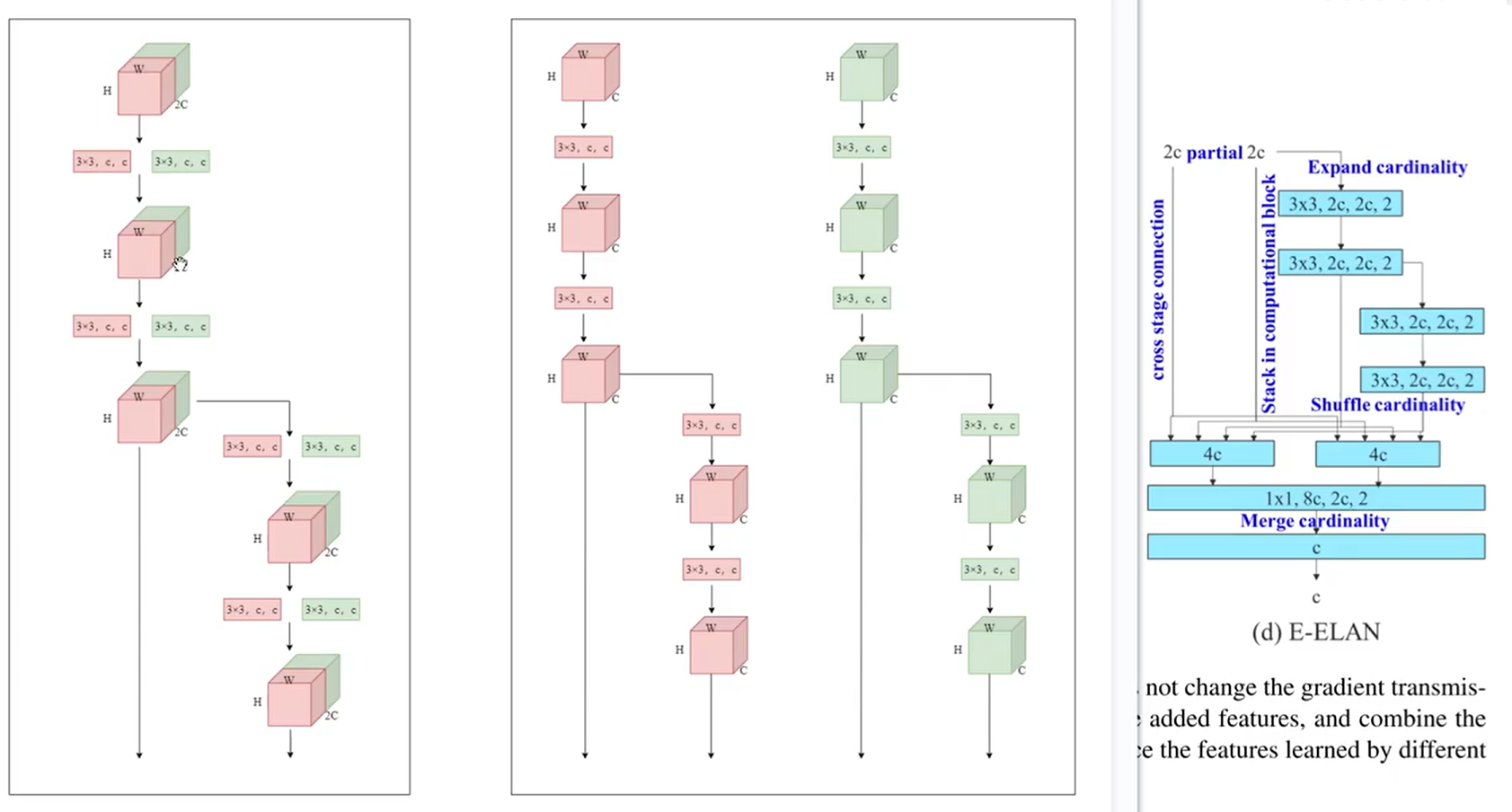
等價於並行兩個ELAN結構
實現
1 | [-1, 1, DownC, [160]], # 2-P2/4 |
模型縮放
因為ELAN涉及拼接,因此縮放需特別設計
對應關係 :
- yolov7 yolov7x
- 額外多一條由兩個卷積構成支路 : 擴大模型深度
- 特徵輸入的數量,concat輸出的數量,過渡的卷積通道數都變成 1.25倍 : 擴大模型寬度
- yolov7-w6 yolov7-e6 yolov7-e6e yolov7-d6
Trainable bag-of-freebies
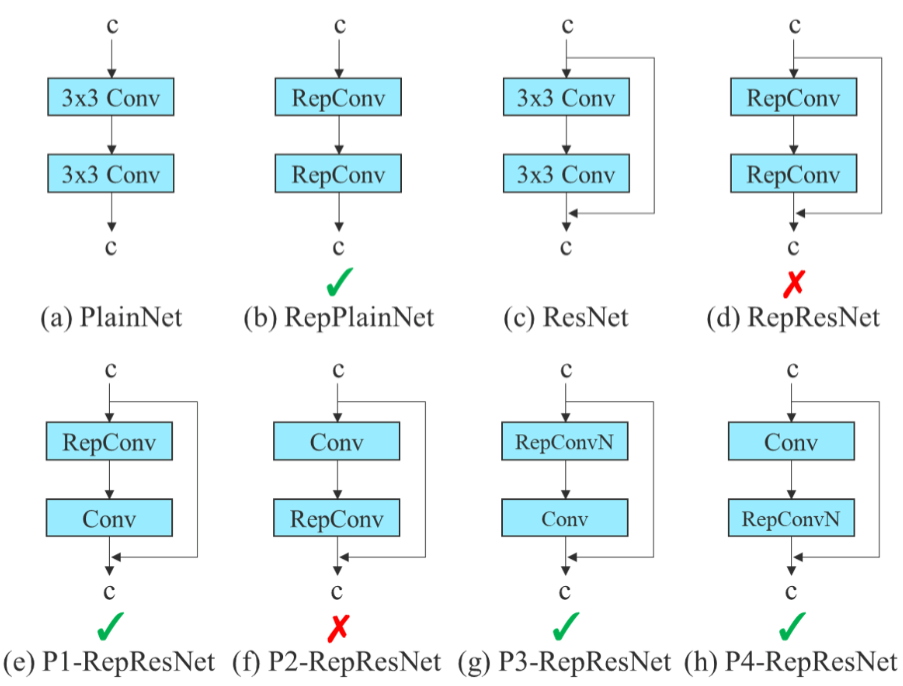
結構重參數化
構造一系列結構(用於訓練),將其參數等架轉換為另一組參數(用於推理),從而將一系列結構轉成另一系列
在vgg取得不錯結果
但直接在殘差模塊上套用,精度降低
本來就有橫等連接(identity connection),會和RepConv起衝突
-
因此橫等連接不要用RepConv或必須使用RepConvN
-
ELAN中卷積直接傳給拼接層也不能直接用RepConv,得用RepConv
-
0.1 版 只有最後使用,且不是拼接或殘差時使用
1 | [75, 1, RepConv, [256, 3, 1]] #使用(b) |
新的標籤分類方法
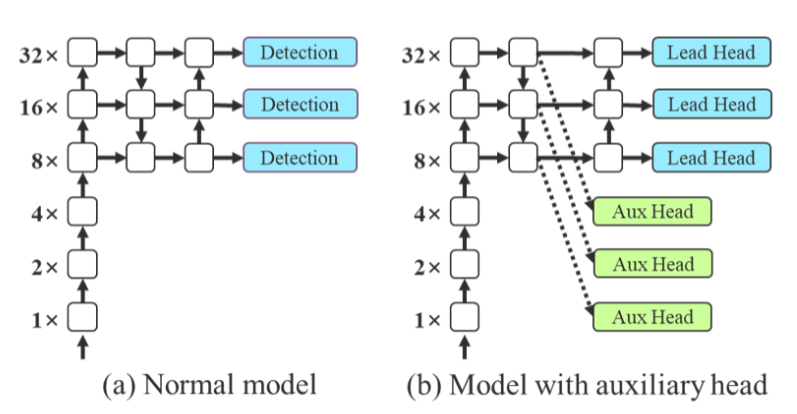
Deep supervision :
- 淺層額外加輔助頭幫忙計算loss,也會反向傳播更新參數
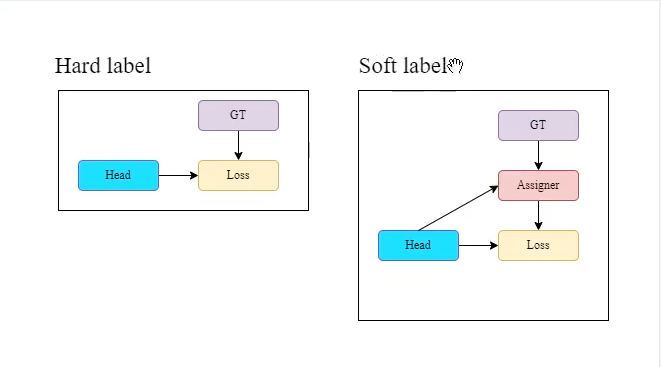
label assignmen:
-
hard label: 真實值(ground truth) 和 檢測值 做LOSS,再來給每個格子標籤
-
soft label: ground truth 和 檢測值 先透過分配器,再跟 ground truth做 Loss來分配
分配器: YOLOX也有用到
1 | compute_loss_ota = ComputeLossOTA(model) # init loss class |
有用到訓練方法
- BN層
- Implicit knowledge
- EMA
網路結構
分為三類
- YOLOv7-tiny, YOLOv7-tiny-silu : 邊緣GPU
- YOLOv7, YOLOv7x : 常規GPU
- YOLOv7-W6, YOLOv7-d6, YOLOv7-e6, YOLOv7-e6e : 雲端GPU
YOLOv7
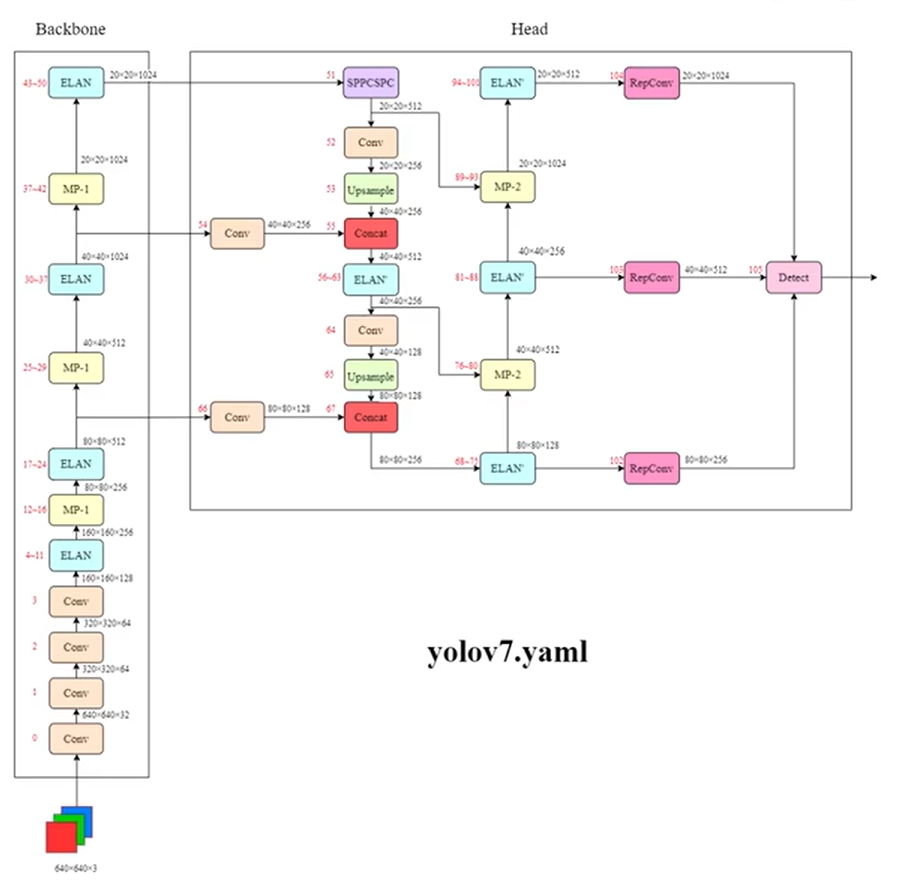
BackBone
Conv
conv2d + bn + silu
1 | class Conv(nn.Module): |
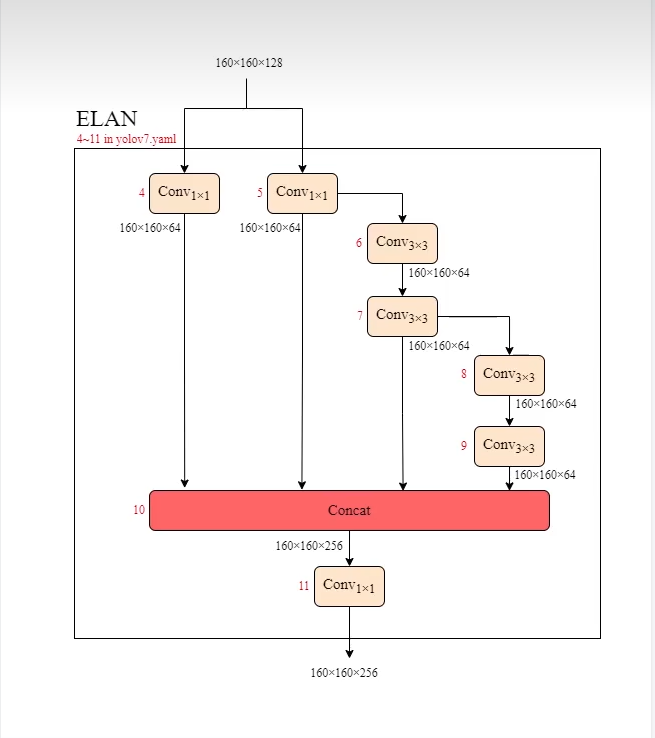
ELAN
右邊卷積 構成2條支路
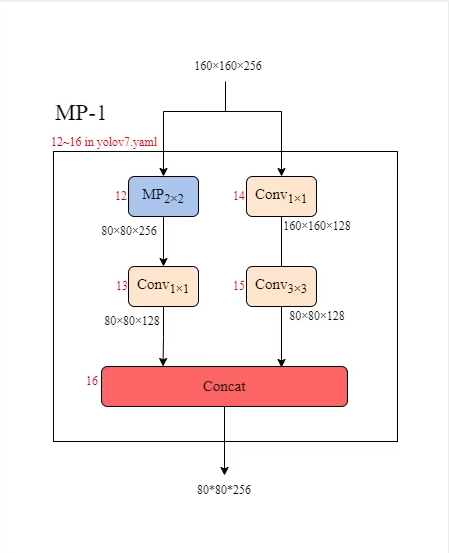
MP1
由於輸出是輸入1/4 , 類似MaxPool
Head
SPPCSPC
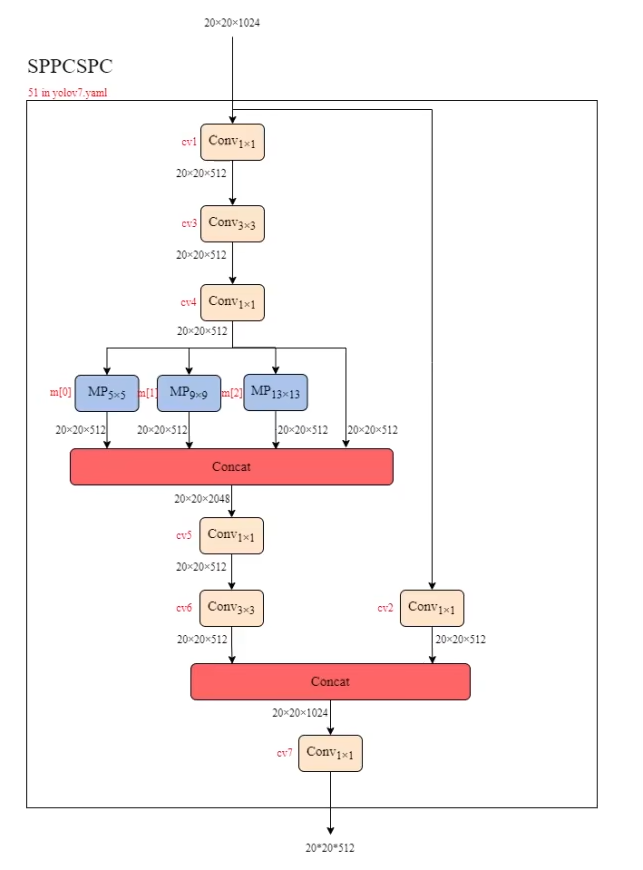
1 | class SPPCSPC(nn.Module): |
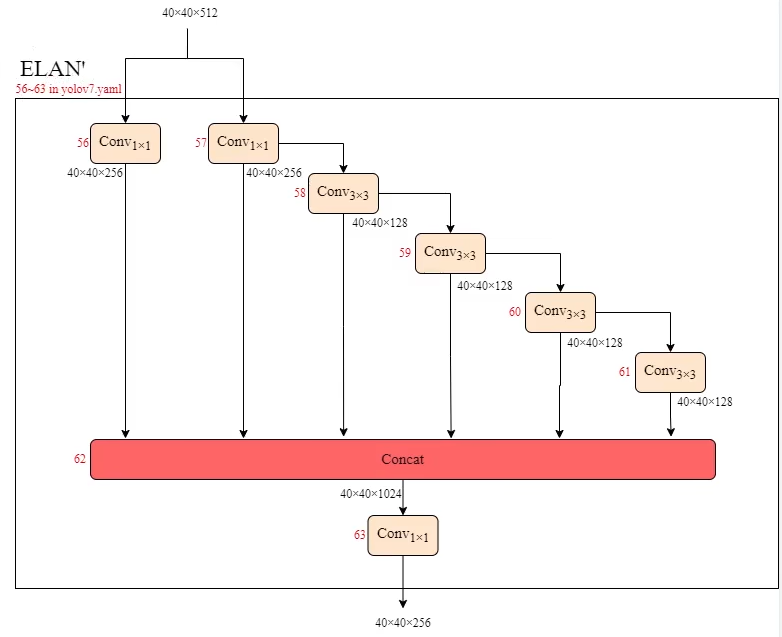
ELAN’
右邊卷積 構成4條支路
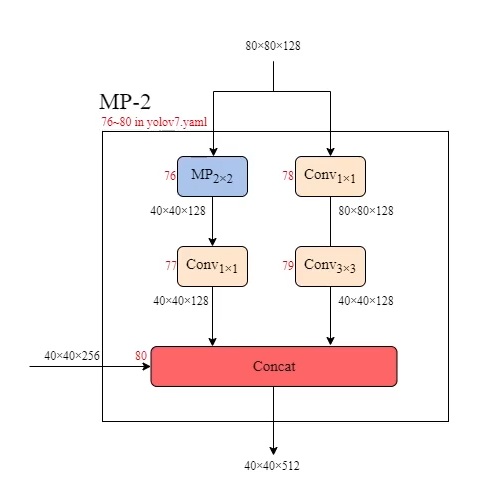
MP2
和MP1幾乎一樣,只是多了左側會傳東西
RepConv
1 | [75, 1, RepConv, [256, 3, 1]] |
部署時 : 只用一個二維卷積
訓練時 : 三條支路(3x3,1x1,橫等連接)
1 | if deploy: |
Detect
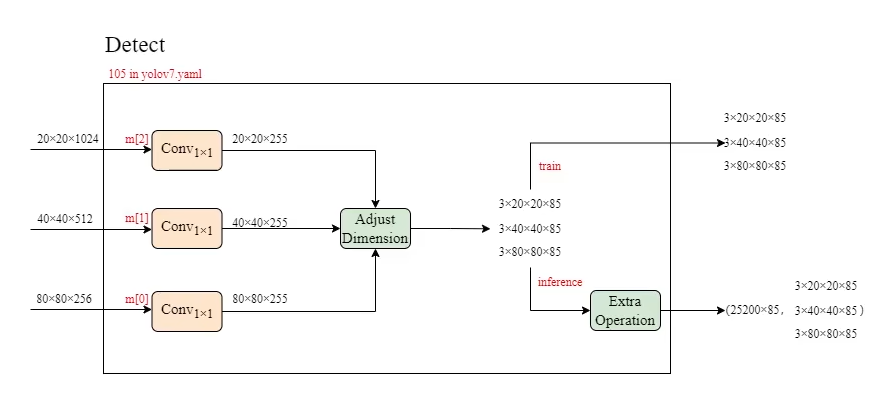
1 | self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv |
本部落格所有文章除特別聲明外,均採用 CC BY-NC-SA 4.0 許可協議。轉載請註明來自 OPH BLOG!
評論
ValineDisqus




