
GPT
NLP 兩大模型
- Bert : 基於上下文預測 (完型填空)
- Gpt : 基於上文預測 (字回歸模型)
難度 : Gpt > Bert
Gpt-1
transformer decoder
論文公式
將模型接全連接層分類進行什麼動作,再進行微調
Gpt-2
不接全連接層不微調,採 zero-shot
透過擴充上文暗示,讓模型知道做什麼
模型輸入 = 自行輸入 + 擴充暗示
ex:
- 二分類 - 高興 vs 不高興
我今天晚上吃大餐,通過這句話我是高興還不高興(暗示) - 實體辨識(Ner)
我今天晚上吃鍋貼,上句話哪個是食物
以上為訓練時所做
困境 : 實際說話,我們是不會加提示,因此預測結果並不會表現很好
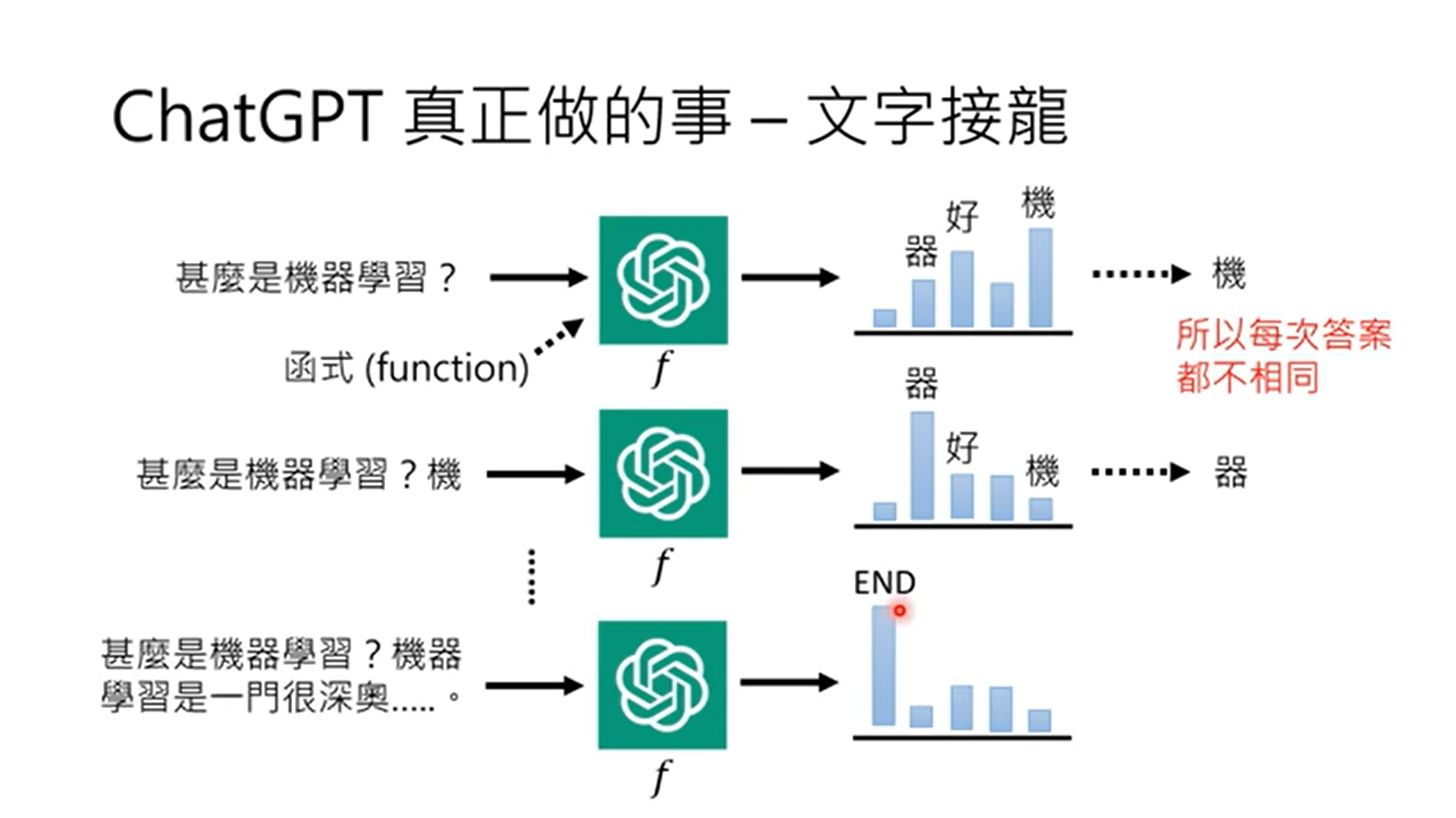
Gpt-3
一言以蔽之 文字接龍
得到生成每個字機率
持續更新中…
本部落格所有文章除特別聲明外,均採用 CC BY-NC-SA 4.0 許可協議。轉載請註明來自 OPH BLOG!

評論
ValineDisqus




